K-mean clustering Algorithm and it's Use in the security domain


K-mean Clustering:
k-means is a prototype based, partitional clustering technique that attempts to find a user specified number of clusters which are represented by their centroids. Clustering algorithms group items together based on some metric of similarity. This is often done by finding the “centroid” of the different possible groups in the dataset, though not exclusively.
As a machine Learning algorithm K-Means clustering is an Unsupervised Learning algorithm therefore does not involve the target output which means no training is provided to the system and the system must learn on its own through determining and adapting to the structural characteristics in the input patterns.
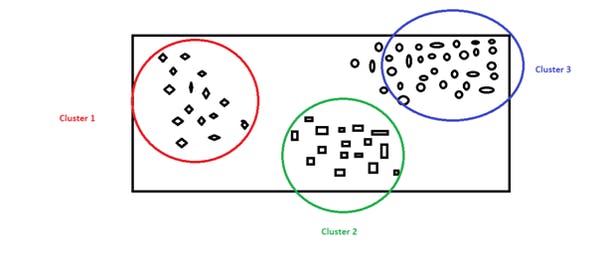
K Means Clustering Algorithm is the most popular algorithm. K-Means is an iterative algorithm. Let’s imagine we have a set of unlabeled data and we want to group the dataset into three clusters. K-Means the algorithm will assign each data point to one of the K groups based on the feature and similarities.
Steps for K-mean Clustering:
In general, K-means clustering can be broken down into these steps,
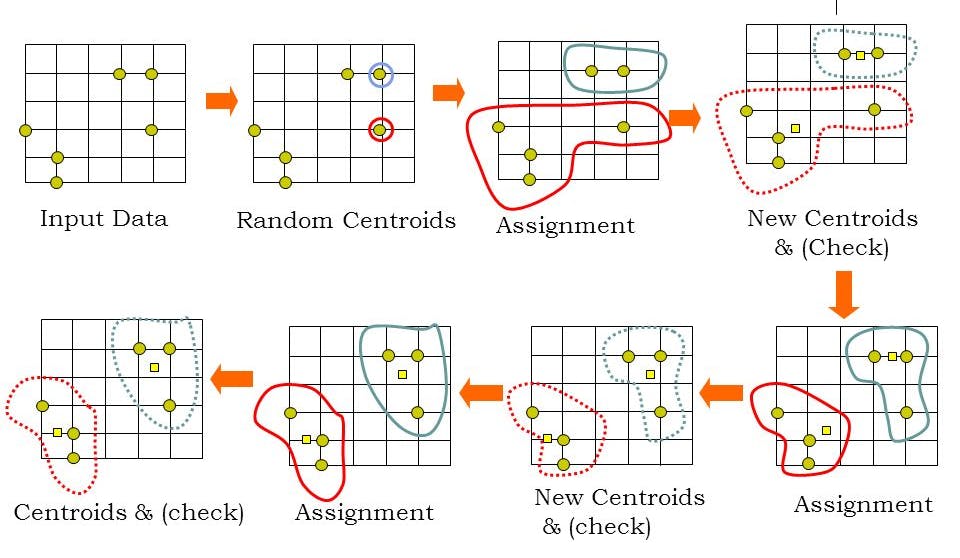
We will define the value of K which means we are going to create a K number of clusters
Place all instances into subsets, where the number of subsets is equal to K
Based on these centroids, assign each point to a specific cluster.
Calculate the distances from every point to the centroids, and assign points to the clusters where the distance from centroid is the minimum.
After the points have been assigned to the clusters, for each cluster, a new centroid is calculated as the mean of all points in the cluster. From the previous step, we have a set of points which are assigned to a cluster. Now, for each such set, we calculate a mean that we declare a new centroid of the cluster
After each iteration, the centroids are slowly moving, and the total distance from each point to its assigned centroid gets lower and lower. The above steps are repeated until the training process is finished that is until there are no more changes in cluster assignment.
Use in Security Domain:
K-means clustering can safely be used in any situation where data points can be segmented into distinct groups/classes.
1. IT Alert based Clustering:
By clustering of operational alerts, we can identify the categories of alerts could be network related, Database related or application related alerts or mean-time to repair the alert or system failure predictions.
2. Identifying crime localities:
with data related to crimes available in specific localities in a city, the category of crime, the area of the crime, and the association between the two can give quality insight into crime-prone areas within a city or a locality.
3. cyber-profiling criminals:
cyber-profiling is the process of collecting data from individuals and groups to identify significant co-relations. the idea of cyber profiling is derived from criminal profiles, which provide information on the investigation division to classify the types of criminals who were at the crime scene.
4. Fraud detection:
Identifying the fraud from the historical dataset and cluster them into one group.